반응형
df.groupby() 함수는 Pandas 데이터프레임에서 그룹화 작업을 수행하는 데 사용됩니다. 이 함수를 사용하면 데이터프레임의 열 값을 기준으로 데이터를 그룹화하고, 그룹화된 데이터에 대해 집계, 변환 또는 다양한 연산을 수행할 수 있습니다.
메서드 구문:
# 함수 구문
grouped = df.groupby(by)주요 매개변수:
- by: 그룹화 기준이 될 열 이름 또는 열 이름의 리스트입니다.
예시 코드:
import pandas as pd
# 샘플 데이터프레임 생성
data = {
'Category': ['A', 'B', 'A', 'B', 'A', 'C'],
'Value': [10, 20, 15, 25, 30, 5]
}
df = pd.DataFrame(data)
# 'Category' 열을 기준으로 데이터프레임을 그룹화
grouped = df.groupby('Category')
# 그룹별 합계 계산
grouped_sum = grouped['Value'].sum()
# 그룹별 평균 계산
grouped_mean = grouped['Value'].mean()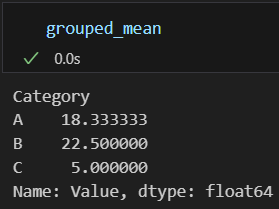
위의 코드에서는 샘플 데이터프레임을 생성하고, df.groupby() 함수를 사용하여 'Category' 열을 기준으로 데이터를 그룹화합니다. 그룹화된 데이터를 통해 그룹별 합계와 평균을 계산합니다.
df.groupby() 함수를 사용하면 데이터프레임을 기준 열의 값에 따라 여러 그룹으로 분할할 수 있으며, 그룹별로 데이터를 조작하고 요약할 수 있습니다. 이는 데이터의 세분화 및 집계 작업에 유용합니다.
반응형
'Python > Pandas' 카테고리의 다른 글
| pandas df.pivot_table() 함수 활용하기 (0) | 2023.12.13 |
|---|---|
| pandas grouped.aggregate() 함수 활용하기 (0) | 2023.12.12 |
| pandas df.apply() 함수 활용하기 (2) | 2023.12.08 |
| pandas df.fillna() 함수 활용하기 (0) | 2023.12.07 |
| pandas df.rename() 함수 활용하기 (4) | 2023.12.06 |



